Part I - Roadmap¶
- Python 簡介
- 開發環境介紹
- 變數
- 字串
- 輸入與輸出
- 判斷式
Python 簡介¶
- Python是一種物件導向、直譯式的電腦程式語言
- 語法簡單,簡潔易懂
- 可以做很多事情...
應用¶
- [網路爬蟲]:urllib、requests、lxml、beautiful_soup、scrapy、selenium
- [資料庫串接]:sqlite3(sqlite)、MySQLdb(MySQL)、pymssql(MSSQL)、Psycopg(PostgreSQL)
- [自然語言]:NLTK、jieba
- [統計應用]:pandas、numpy、scipy、matplotlib
- [機器學習]:scikit-learn、TensorFlow
- [影像處理]:PIL、opencv
- [網站架設]:Django、Flask
- [網路分析]:scapy
- [GUI設計]:tkinter、PyQt
- [軟硬整合]:raspberry pi 樹莓派、Arduino
- [遊戲開發]:pygame
- [App開發]:kivy
- [各種服務的API串接]:Bot
使用jupyter撰寫&執行 第一隻Python 程式¶
新增一個Notebook (New > Notebooks | Python [default])
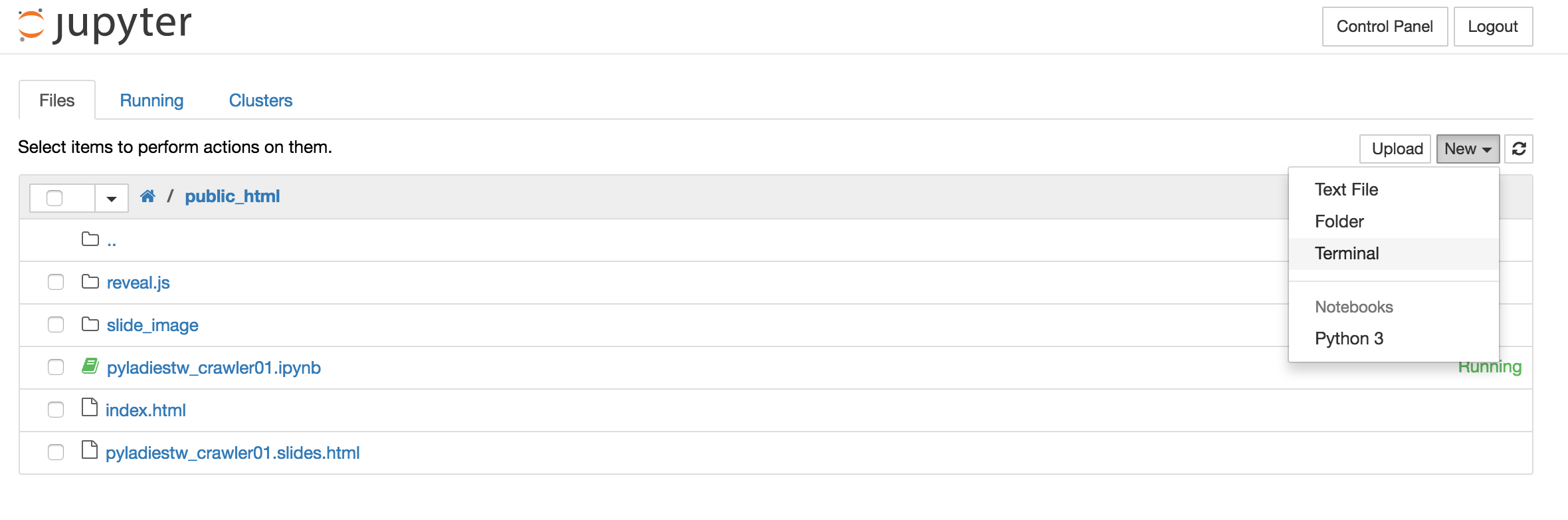
輸入程式碼 print ("Hello PyLadies"),按下介面上的 >| 或是用快捷鍵 Ctrl+Enter、Shift+Enter編譯執行
print ("Hello PyLadies")
!注意¶
- 如果有用到上方cell的程式碼內容,需要先編譯執行上方cell的程式碼
- 如果針對現在的cell多次編譯執行,並不會影響到上方cell已編譯執行後的結果
變數¶
- 變數是一個容器,是資料的儲存空間
- 在程式中「=」是「賦值」的意思:將右邊的資料儲存到左邊的變數
- my_score = 96
- pi = 3.14159
- url = "http://blog.marsw.tw"
- my_score、pi、url 都是自行命名的變數
- 可以命名的字元:_、0~9、a~Z
!注意¶
- 不能以數字開頭
- 不能與保留字相同 (ex: import, for, in, str....)
- 大小寫有別
- 好的命名方式會讓程式碼容易閱讀
- xyz = "http://blog.marsw.tw" vs.
url = "http://blog.marsw.tw"
- xyz = "http://blog.marsw.tw" vs.
變數型別¶
- type(變數):印出此變數的型別
my_score = 96
pi = 3.14159
url = "http://blog.marsw.tw"
print (type(my_score))
print (type(pi))
print (type(url))
Python 是一個動態性的語言¶
- 同樣的變數可以隨時更動他的變數型別
my_score = 96
print (type(my_score))
my_score = 96.0
print (type(my_score))
my_score = "96"
print (type(my_score))
數值¶
- 整數 integer:int
- 小數 float:float
- 運算元:+ - * / % **
a = 96
b = 80
c = a+b
print (a+b,c)
print (a-b)
print (10*3) # 乘法
print (10/3) # 除法
print (10%3) # 取餘數
print (10**3) # 次方
運算元的簡潔寫法¶
- a+= b : a = a+b
- a-= b : a = a-b
- a*= b : a = a*b
count = 0
count+= 1
print (count) # count = 1
count*= 3
print (count) # count = 3
count-= 2
print (count) # count = 1
字串(string)¶
- 可以直接給定詞句
- 也可以給空白句
- 可以相+、相*
my_string = "Hi"
my_string2 = ""
my_string2 = my_string2 + "Py" + 'Ladies'
my_string3 = "Hello"*4
print (my_string)
print (my_string2)
print (my_string3)
!注意¶
- 用「成對的」雙引號( " ) 或是單引號( ' ) ,將字串包住
!注意¶
- 字串與數值不可一同運算
my_string = "123"
my_int_number = 456
print (my_string+my_int_number) # TypeError: must be str, not int
input1 = 123
input2 = "456"
input3 = "5566.123"
print (str(input1)+input2) #str+str
print (input1+int(input2)) #123+456=579
print (float(input3)+input1) #5566.123+123=5689.123
print (int(input3)) # ValueError: invalid literal for int() with base 10: '5566.123'
輸入與輸出¶
- input(提示字):從鍵盤輸入值
- 輸入的值會儲存為字串型別
- print(物件):輸出物件到螢幕上
- 可以用 , 印出多個物件(印出後,會以空格分隔物件)
a = input("a=") # "a=" 是提示字,讓我們知道電腦在等我們輸入
b = input("b=")
print ("a+b=",a+b) # input進來是字串
a = input("a=") # "a=" 是提示字,讓我們知道電腦在等我們輸入
b = input("b=")
print ("a+b=",a+b) # input進來是字串
input()可以讓我們跟電腦互動
而不單單只是讓電腦print()東西出來而已
互動的計算機¶
a = input("a=") # "a=" 是提示字,讓我們知道電腦在等我們輸入
a = int(a) # input進來是字串,要做數值運算要用int()轉換
# 以上也可以簡寫為 a = int(input("a="))
print ("a*2=",a*2)
print ("a^2=",a**2)
問候機器人¶
a = input("請問您是誰? ")
print ("你好",a) # 用,分隔會印出空格
print("你好"+a) # 可以用字串相加,就不會有空格
判斷式:if/elif/else¶
- if 是判斷式必備的
- if:一種選項,滿足條件,才執行某動作
- elif:有更多條件,滿足的話執行某動作,須伴隨 if 存在
- else:當以上條件都不滿足,執行某動作,須伴隨 if 存在
- if 布林型別: 如果布林型別 == True,就做這裡面的事情
if 語法:¶
if lists[0] == 0:
...
elif lists[0] == 1:
...
else lists[0] == 2:
...
# 基本的判斷式是由 if 構成
a = 61
if a>=60:
print ("及格")
# 不符合條件,因此什麼都沒有印出
a = 58
if a>=60:
print ("及格")
# 如果希望處理判斷條件之外的狀況,可以用else
a = 58
if a>=60:
print ("及格")
else:
print ("不及格")
如果有很多個條件,一個 if 不夠用,可以用 elif¶
a = 11
b = 8
if a>b:
print ("a>b")
elif a<b:
print ("a<b")
else:
print ("a<=b")
print ("這是判斷式外的區塊")
!注意¶
- Python是靠「縮排」(四個空格),來斷定程式碼屬於那一個區塊。
- if/elif/else 後面記得要有冒號(:)
a = 11
b = 8
# 第1組判斷式
if a%2==0:
print ("a is even")
# 第2組判斷式
if a>b:
print ("a>b")
elif a<b:
print ("a<b")
else:
print ("a==b")
- 一個 if 就是一組判斷式
- 兩組判斷式是不互相影響的
- 如果 a = 11, b = 8 ,
- 第1組判斷式沒有符合任何條件就什麼事都不會做,
- 第2組判斷式會印出a>b,不受到第1組判斷式沒有任何條件符合的影響
- 如果 a = 6, b = 8 ,
- 第1組判斷式會印出a is even,
- 第2組判斷式會印出a<b
- 如果 a = 11, b = 8 ,
# 如果x是奇數,就保留原值,否則-1
x = 9
result = x if (x%2==1) else x-1
print(result)
Part II - Roadmap¶
- 序列型別
- 序列共同介面
- 序列的應用

my_list1 = ["a",2016,5566,"PyLadies"]
my_list2 = []
my_list3 = my_list1+[2016,2016.0]
my_list4 = [1,2,3]*3
print (my_list1,bool(my_list1))
print (my_list2,bool(my_list2))
print (my_list3)
print (my_list4)
# 索引值 0 , 1 , 2 , 3 , 4 , 5
my_list = ["a",2016,5566,"PyLadies",2016,2016.0] # 這是一個長度為6的串列
print ("The 4th element",my_list[3])
print ("The last element",my_list[-1]) # 等同於拿取索引=6-1=5的元素
print ("The second-last element",my_list[-2]) # 等同於拿取索引=6-2=4的元素
# 索引值 0 , 1 , 2 , 3 , 4 , 5
my_list = ["a",2016,5566,"PyLadies",2016,2016.0]
b = my_list[1]
my_list[2] = 2017
print(b)
print(my_list)
「字串」跟「串列」很像¶
- 字串的每個元素都是一個字元(字母或符號)
- 用同樣的方式存取元素
# 索引值 0123456789....
my_string = "PyLadies Taiwan"
print ("The 1st element of my_string = ",my_string[0])
print ("The 8th element of my_string = ",my_string[7])
print ("The last element of my_string = ",my_string[-1])
!注意¶
- 索引不能超過界線
print(my_string[20])
my_tuple1 = ("a",2016,5566,"PyLadies")
my_tuple2 = ()
my_tuple3 = my_tuple1+(2016,2016.0)
my_tuple4 = (1,2,3)*3
my_tuple5 = (1,) # 加 ,
my_int = (1) # 不加 ,
print (my_tuple1,bool(my_tuple1))
print (my_tuple2,bool(my_tuple2))
print (my_tuple3)
print (my_tuple4)
print (my_tuple5)
print (type(my_tuple5)) # <class 'tuple'>
print (my_int)
print (type(my_int)) #<class 'int'>
print (my_tuple1[1])
型別轉換¶
s = "PyLadies" # <class 'str'>
l = ["a",2016,5566,"PyLadies"] # <class 'list'>
t = ("a",2016,5566,"PyLadies") # <class 'tuple'>
print(type(list(t)))
print(type(tuple(l)))
print(list(s))
print(tuple(s))
比較運算¶
- 從第1個元素開始比,如果一樣就再比第2個元素...,直到不一樣就停止比對。
- 如果元素型別不同,會出現錯誤!
s1 = "Hi"
s2 = "Hello"
print(s1<s2) # i 的 ASCII 比 e 大
l1 = ["a",2016,5566,"PyLadies"]
l2 = ["a",2016,5566,"PyLadies"]
print(l1==l2)
l2+= [2017]
print(l2>l1,l2)
l3 = ["a",2016,"PyLadies"]
print(l1<l3) # 如果元素型別不同,會出現錯誤!
my_string = "PyLadies Taiwan"
my_list = ["a",2016,5566,"PyLadies",2016,2016.0]
print ("Length of my_string = ",len(my_string))
print ("Length of my_list = ",len(my_list))
數值計算¶
- max(串列):序列中最大值
- min(串列):序列中最小值
- sum(串列):序列總和,針對全數字序列才有用
l = [3, 4, 2.1, 1]
t = (3, 4, 2.1, 1)
s = "PyLadies" # ASCII=> A = 65 ; a = 97
print(max(l),min(l),sum(l))
print(max(t),min(t),sum(t))
print(max(s),min(s))
print(sum(s))
score_of_each_student = [85,70,54,87,98,66,40]
avg_score = sum(score_of_each_student) / len(score_of_each_student) # len=7
print ("全班分數落差為",max(score_of_each_student)-min(score_of_each_student))
print ("全班平均為",avg_score)
my_string = "PyLadies Taiwan"
if "PyLadies" in my_string:
print ("\"PyLadies\" found")
if "Python" in my_string:
print ("\"Python\" found")
if "Taiwan" in my_string:
print ("\"Taiwan\" found")
my_list = ["a",2016,5566,"PyLadies",2016,2016.0]
print(2016 in my_list)
print("2016" in my_list)
my_string = "PyLadies Taiwan"
my_list = ["a",2016,5566,"PyLadies",2016,2016.0]
print ("The time 'a' appears in my_string = ",my_string.count('a'))
print ("The time '2016' appears in my_string = ",my_list.count(2016))
article = """
Bubble tea represents the "QQ" food texture that Taiwanese love.
The phrase refers to something that is especially chewy, like the tapioca balls that form the 'bubbles' in bubble tea.
It's said this unusual drink was invented out of boredom.
"""
print (article.count('in'))
[ 序列的應用 ]¶
s = "Hi PyLadies Taiwan"
l = s.split(" ")
print (l)
print (s.split(" ",1))
print (s)
print (l[0])
print (l[-1])
article = """
Bubble tea represents the "QQ" food texture that Taiwanese love.
The phrase refers to something that is especially chewy, like the tapioca balls that form the 'bubbles' in bubble tea.
It's said this unusual drink was invented out of boredom.
"""
word_of_article = article.split(" ")
print (word_of_article.count("in"))
Part III - Roadmap¶
- 迴圈與迭代
[ 迴圈與迭代 ]¶
迭代的概念是「一個接著一個處理」, 需要有供給可迭代的物件的提供者,讓接收方一個個處理。
序列可以用索引值標示元素的概念,就是很好的提供者, 而處理這些迭代物件的接收方,在Python裡最常用的就是for迴圈!
[think]¶
- 我想要輸入10個不相等的變數
- 我想要輸入一串數組ex:(1,2,3,4,5),然後印出相加的總和
- 我想要算出字串 "「1」、「5」、「7」、「3」、「2」、「6」" 出現數字的總和
while¶
- 處理「未知」次數的重複狀況
- while(條件成立): 執行某事
while 語法:¶
while lists[0] == 0:
...
# 輸入5個不相等的數字
my_list = []
while(len(my_list)<5):
input_word = input("請輸入數字")
input_num = int(input_word)
if input_num not in my_list: #判斷,不重複的數字才加入(append)一個元素x到List裡.
my_list.append(input_num)
print (my_list)

for 語法:¶
for number in lists:
...
for i in [1,4,7,9]:
print ('i=',i)
my_list=[1,2,5,7,6]
for i in my_list:
print (i)
for i in "Hello":
print (i)
我想要算出字串 "「1」、「5」、「7」、「3」、「2」、「6」" 出現數字的總和¶
data = "「1」、「5」、「7」、「3」、「2」、「6」"
data = data.replace("「","") # replace() 替換
data = data.replace("」","")
print (data)
print (data.split("、"))
#接續
my_sum = 0
for i in data.split("、"):
my_sum+=int(i)
print (i,my_sum)
print ("The sum of list is",my_sum)
[練習]¶
- 輸入10個不重複的數字,印出其中為奇數的數字
- 重複輸入數字
- 如果輸入的數字存在串列中,則繼續輸入
- 取得串列的各個元素
- 如果餘數=1才印出
range(start,end,stride)¶
- range也是一種序列型別,會回傳一系列能迭代的物件,是可迭代者
- start 是 inclusive,預設是 0 開始
- end 是 exclusive,必填值
- stride 是跳幾次切割,預設是1
- stride 為負值則由尾端向前端取,需讓start>end
注意!¶
- start > end ,則等同於空
- stride 不得為 0
print('range(5) ',list(range(5))) # 只有一個代表end
print('range(2,5) ',list(range(2,5)))
print('range(2,5,2) ',list(range(2,5,2)))
print('range(5,0) ',list(range(5,0))) # start > end ,則等同於空
print('range(5,0,-1)',list(range(5,0,-1))) # stride 為負值則由尾端向前端取
print('range(0,5,-1)',list(range(0,5,-1))) # stride 為負值則由尾端向前端取,需讓start>end
print (list(range(10)))
print (list(range(1,10)))
print (list(range(1,10,2)))
print (list(range(10,0,-1)))
for i in range(1,5+1):
print ("*"*i)
for i in range(5,0,-1):
print ("*"*i)
配合迴圈,這樣可分別拿到0~2的數值,可以當成串列索引¶
print(list(range(3)))
for i in range(3):
print(i)
想像我有一個紀錄員工年資的串列,薪水是依照 年資*100+22000 的公式去計算
# 土法煉鋼,一個個員工慢慢列
l = [5.5, 9, 10]
print("員工1的薪水",l[0]*100+22000)
print("員工2的薪水",l[1]*100+22000)
print("員工3的薪水",l[2]*100+22000)
# ...
3個員工,我就要寫3行告訴我各個員工的薪水,那如果有100個員工...
如果有一個紀錄串列各個索引值0~n的資料型別,就會很方便
# 使用迴圈
l = [5.5, 9, 10]
for i in range(3):
print("i=",i, "員工{}的薪水=>".format(i+1), l[i]*100+22000)
- 串列也是一個可迭代者,
- 如果要取所有串列的元素,除了用索引拿取 range(0,len(串列)),
- 也可以直接用for迴圈處理:
l = [5.5, 9, 10]
for i in l:
print(i)
l = [5.5, 9, 10]
for i in l:
print(i*100+22000)
# 對比 range() 寫法
l = [5.5, 9, 10]
for i in range(3):
print(l[i]*100+22000)
想要印出第幾位員工,因為直接用串列當成可迭代者,需要紀錄現在是第幾個索引(index)
l = [5.5, 9, 10]
count= 0 # 紀錄現在的索引(index)
for i in l:
print("員工{}的薪水".format(count+1), i*100+22000)
count+=1 # count = count+1
# 對比 range() 寫法
l = [5.5, 9, 10]
for i in range(3):
print("員工{}的薪水".format(i+1), l[i]*100+22000)
range( ) 更彈性的寫法¶
range(數值)中,數值最好保持彈性,
如果寫死,一但串列增加元素,就得改值,很不方便!
l = [5.5, 9, 10, 2.3] # 新增一個元素 -> 2.3
for i in range(4):
print("員工{}的薪水".format(i+1), l[i]*100+22000)
l = [5.5, 9, 10, 2.3] # 新增一個元素 -> 2.3
#print(len(l)) --> 4
for i in range(len(l)): # 串列有多長就用多長
print("員工{}的薪水".format(i+1), l[i]*100+22000)
[練習] 調分公式:開根號,再乘10¶
有一列學生的成績 l = [32,56,58,62,79,82,98],
我希望將學生調分:
學生1 56.568542494923804
學生2 74.83314773547883
學生3 76.15773105863909
學生4 78.74007874011811
學生5 88.88194417315589
學生6 90.55385138137417
學生7 98.99494936611666
Hint:
import math
print(math.sqrt(9))
print(math.sqrt(10))
- 練習一: 使用 range()
l = [32,56,58,62,79,82,98]
import math
for i in range(__):
print("學生{}".format(__),math.sqrt(___)*10)
- 練習二: 使用串列,配合紀錄現在索引位置的物件
l = [32,56,58,62,79,82,98]
import math
count = 0
for i in l:
print("學生{}".format(__),math.sqrt(___)*10)
count = _____
答案¶
#練習一: 使用 range()
l = [32,56,58,62,79,82,98]
import math
for i in range(len(l)):
print("學生{}".format(i+1),math.sqrt(l[i])*10)
print("----------分隔線----------")
#練習二: 使用串列,配合紀錄現在索引位置的物件
l = [32,56,58,62,79,82,98]
import math
count = 0
for i in l:
print("學生{}".format(count+1),math.sqrt(i)*10)
count = count+1 # count+=1
Part IV - Roadmap¶
- 字典
- 函式
字典 (Dictionary)¶
- 字典名稱[key]: 字典以鍵值key去存取資料value
- 鍵值key: 很像是串列的索引(index)
- 查找速度快
- 設定值: 字典名稱[key]=value
- 拿取值: 字典名稱[key]
- key:value
{ "the":10 , "a" :9 , "of" :6 , "in" :6 }
!注意¶
- 字典是「無順序排放」的資料型別
- 字典是存key,然後以key去找資料value
- key 不可重複
my_dict = {} #空字典
my_dict["the"] = 10
my_dict["a"] = 9
my_dict["of"] = 6
my_dict["in"] = 6
my_dict2 = {"the":10,"a":9,"of":6,"in":6}
print (my_dict)
print (my_dict2)
print (my_dict["the"])
!注意¶
- 直接使用字典不存在的key去找資料會有錯誤!
#字典'存在'的 key
my_dict = {"the":10,"a":9,"of":6,"in":6}
print ("the" in my_dict)
print (my_dict["the"])
#字典'不存在'的 key
my_dict = {"the":10,"a":9,"of":6,"in":6}
print ("with" in my_dict)
print (my_dict["with"])
字典 - 以迴圈處理¶
- 字典以鍵值key去存取資料value
my_dict = {"Mars":20,"姿君":25,"毛毛":10}
for key in my_dict:
print(key,my_dict[key])
字典與串列的差異¶
- 串列(list):索引index => 值value
- 字典(dict):鍵值key => 值value
如何把串列(list)變成字典(dict)¶
#寫法一
l = [["姿君",25],["Mars",20],["毛毛",10]] #list
my_dict = {} ##空字典
for item in l:
name = item[0]
score = item[1]
my_dict[name]=score # 設定值:字典名稱[key]=value
print("拿取值",my_dict[name]) # 拿取值:字典名稱[key]
print(my_dict)
#寫法二
l = [["姿君",25],["Mars",20],["毛毛",10]]
my_dict = {} ##空字典
for name,score in l:
my_dict[name]=score # 設定值:字典名稱[key]=value
print(my_dict)
函式 Function¶
- 參數(patameter)是定義函式時指定的名稱,可有可無
- 引數(argumwnt)是函數呼叫時傳入的真正物件,在呼叫時會建立參數和引數的綁定關係。
- 需和參數的個數一樣
- 函式內的程式碼可以有各種可能(eg. 迴圈、判斷式、運算...)
- return 回傳,可有可無(若無會回傳None),用tuple可回傳多個物件
函式 語法:¶
使用關鍵字 def 宣告。
#定義函式
def 函式名稱(參數1,參數2,...):
程式碼
程式碼
程式碼
return 物件1,物件2,物件3
#呼叫函式
函式名稱(引數1,引數2,...)
- 自己打造工具
- 利用呼叫,方便重複利用
- 程式碼更為簡潔
def 洗衣機():
注水
旋轉清洗
排水
旋轉脫水

到咖啡機弄一杯咖啡
- 打開開關
- 放下杯子
- 選擇「咖啡類別」,按下製作
- 咖啡機「製作咖啡」
- 得到一杯咖啡


Recall¶
還記得我們使用過不少工具:print()、ord()、max()...,
這些都是內建函式Bult-in Function,他們背後的運作原理可能像是這樣:
print(max([1,2,7,9,10]))
a=max([1,2,7,9,10])
print(a)
def my_max(data):
num_max = -999999999
for i in data:
if i>=num_max:
num_max = i
return num_max
print(my_max([1,2,7,9,10]))
練習 - 自己寫一個 Function¶
判斷是否為閏年:
從西元元年起,每隔4年為閏年,但逢百年不算在內,唯一的例外是400年或400年的倍數,仍舊為閏年。不為閏年的即為平年。
- 西元年可被4整除,但不能被100整除
- 西元年份除以400可整除
答案:
- 閏年:2000、2400
- 平年:1800、1900、2100、2200、2300、2500
Hint:
- 判斷式:if、elif、else
- a%b:可以取a除以b的餘數
def is_leap(year):
leap = False
...
你的程式碼
...
return leap
print(is_leap(2000))
print(is_leap(1800))
答案¶
def is_leap(year):
leap = False
if year%4==0 and year%100!=0:
leap = True
elif year%400==0:
leap = True
return leap
print(is_leap(2000))
print(is_leap(1800))